https://projectreactor.io/docs/core/release/reference/#advanced
Reactor 3 Reference Guide
10:45:20.200 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription) (1) 10:45:20.205 [main] INFO reactor.Flux.Range.1 - | request(unbounded) (2) 10:45:20.205 [main] INFO reactor.Flux.Range.1 - | onNext(1) (3) 1
projectreactor.io
9. Advanced Features and Concepts
9.1 ~ 9.5
This chapter covers advanced features and concepts of Reactor, including the following:
- Mutualizing Operator Usage
- Hot Versus Cold
- Broadcasting to Multiple Subscribers with ConnectableFlux
- Three Sorts of Batching
- Parallelizing Work with ParallelFlux
- Replacing Default Schedulers
- Using Global Hooks
- Adding a Context to a Reactive Sequence
- Null Safety
- Dealing with Objects that Need Cleanup
9.1. Mutualizing Operator Usage
From a clean-code perspective, code reuse is generally a good thing. Reactor offers a few patterns that can help you reuse and mutualize code, notably for operators or combinations of operators that you might want to apply regularly in your codebase. If you think of a chain of operators as a recipe, you can create a “cookbook” of operator recipes.
9.1.1. Using the transform Operator
The transform operator lets you encapsulate a piece of an operator chain into a function. That function is applied to an original operator chain at assembly time to augment it with the encapsulated operators. Doing so applies the same operations to all the subscribers of a sequence and is basically equivalent to chaining the operators directly. The following code shows an example:
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
The following image shows how the transform operator encapsulates flows:

The preceding example produces the following output:

9.1.2. Using the transformDeferred Operator
The transformDeferred operator is similar to transform and also lets you encapsulate operators in a function. The major difference is that this function is applied to the original sequence on a per-subscriber basis. It means that the function can actually produce a different operator chain for each subscription (by maintaining some state). The following code shows an example:
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transformDeferred(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
The following image shows how the transformDeferred operator works with per-subscriber transformations:

The preceding example produces the following output:
transformDeferred 사용한 경우 : AtomicInteger ai 값이 subscriber 1,2 같음!

transform 사용한 경우 : AtomicInteger ai 값이 subscriber 1,2 다름 !

가장 큰 차이는 transformDeferred 는 subscribe 시 오퍼레이터가 생성되어 적용된다!!!
transafrom 은 오퍼레이터가 다 박혀버리고 섭스크라이브 언제하던 다 똑같다!
9.2. Hot Versus Cold
So far, we have considered that all Flux (and Mono) are the same: They all represent an asynchronous sequence of data, and nothing happens before you subscribe.
Really, though, there are two broad families of publishers: hot and cold.
The earlier description applies to the cold family of publishers. They generate data anew for each subscription. If no subscription is created, data never gets generated.
Think of an HTTP request: Each new subscriber triggers an HTTP call, but no call is made if no one is interested in the result.
Hot publishers, on the other hand, do not depend on any number of subscribers. They might start publishing data right away and would continue doing so whenever a new Subscriber comes in (in which case, the subscriber would see only new elements emitted after it subscribed). For hot publishers, something does indeed happen before you subscribe.
Hot publisher 는 즉시 데이터 publishing을 시작할 수 있고 새로운 Subscriber 와 상관없이 계속 동작할 것입니다
(이 경우 Subscriber는 subscribe 한 후에 emit 된 새 element 만 보게 됩니다).
One example of the few hot operators in Reactor is just: It directly captures the value at assembly time and replays it to anybody subscribing to it later. To re-use the HTTP call analogy, if the captured data is the result of an HTTP call, then only one network call is made, when instantiating just.
To transform just into a cold publisher, you can use defer. It defers the HTTP request in our example to subscription time (and would result in a separate network call for each new subscription).
On the opposite, share() and replay(…) can be used to turn a cold publisher into a hot one (at least once a first subscription has happened). Both of these also have Sinks.Many equivalents in the Sinks class, which allow programmatically feeding the sequence.
Hot publisher 중 하나인 just 가 있습니다.
값을 assembly 시간에 바로 캡쳐하고 나중에 subscribe 되는시점에 바로 응답합니다.
http 호출로 비유해 보면, 캡쳐된 데이터가 http 호출 결과 인 경우 인스턴스화 시점에 네트워크 호출이 한번만 수행됩니다.
defer 를 통해 Hot -> Cold 변경이 가능합니다. http 요청을 subscribe 시점으로 미루고 각 새 subscribe에 대해 별도의 네트워크 호출이 발생합니다.
반대로 share(), replay(…) 는 Cold -> Hot 변경에 사용됩니다. (최소한 첫번째 구독이 발생 이후)
Consider two examples, one that demonstrates a cold Flux and the other that makes use of the Sinks to simulate a hot Flux. The following code shows the first example:
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
The following image shows the replay behavior:
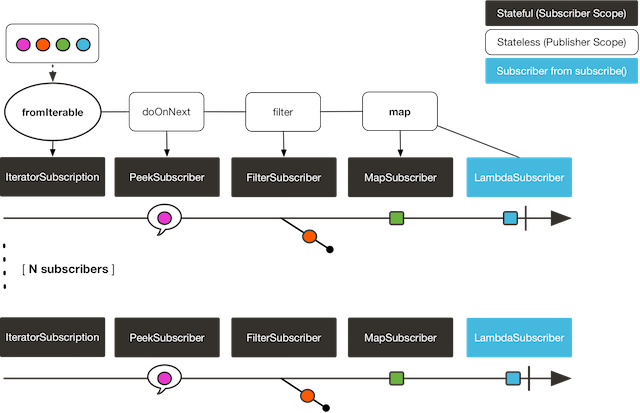
Both subscribers catch all four colors, because each subscriber causes the process defined by the operators on the Flux to run.
Compare the first example to the second example, shown in the following code:
Sinks.Many<String> hotSource = Sinks.unsafe().many().multicast().directBestEffort();
Flux<String> hotFlux = hotSource.asFlux().map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.emitNext("blue", FAIL_FAST);
hotSource.tryEmitNext("green").orThrow();
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.emitNext("orange", FAIL_FAST);
hotSource.emitNext("purple", FAIL_FAST);
hotSource.emitComplete(FAIL_FAST);
| for more details about sinks, see Safely Produce from Multiple Threads by Using Sinks.One and Sinks.Many | |
| side note: orThrow() here is an alternative to emitNext + Sinks.EmitFailureHandler.FAIL_FAST that is suitable for tests, since throwing there is acceptable (more so than in reactive applications). |
1,2 결과

The following image shows how a subscription is broadcast:

Subscriber 1 catches all four colors. Subscriber 2, having been created after the first two colors were produced, catches only the last two colors. This difference accounts for the doubling of ORANGE and PURPLE in the output. The process described by the operators on this Flux runs regardless of when subscriptions have been attached.
9.3. Broadcasting to Multiple Subscribers with ConnectableFlux
Sometimes, you may want to not defer only some processing to the subscription time of one subscriber, but you might actually want for several of them to rendezvous and then trigger the subscription and data generation.
This is what ConnectableFlux is made for. Two main patterns are covered in the Flux API that return a ConnectableFlux: publish and replay.
- publish dynamically tries to respect the demand from its various subscribers, in terms of backpressure, by forwarding these requests to the source. Most notably, if any subscriber has a pending demand of 0, publish pauses its requesting to the source.
- replay buffers data seen through the first subscription, up to configurable limits (in time and buffer size). It replays the data to subsequent subscribers.
A ConnectableFlux offers additional methods to manage subscriptions downstream versus subscriptions to the original source. These additional methods include the following:
- connect() can be called manually once you reach enough subscriptions to the Flux. That triggers the subscription to the upstream source.
- autoConnect(n) can do the same job automatically once n subscriptions have been made.
- refCount(n) not only automatically tracks incoming subscriptions but also detects when these subscriptions are cancelled. If not enough subscribers are tracked, the source is “disconnected”, causing a new subscription to the source later if additional subscribers appear.
- refCount(int, Duration) adds a “grace period.” Once the number of tracked subscribers becomes too low, it waits for the Duration before disconnecting the source, potentially allowing for enough new subscribers to come in and cross the connection threshold again.
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(500);
System.out.println("will now connect");
co.connect();
autoConnect 사용
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
Flux<Integer> autoCo = source.publish().autoConnect(2);
autoCo.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("subscribed first");
Thread.sleep(500);
System.out.println("subscribing second");
autoCo.subscribe(System.out::println, e -> {}, () -> {});
9.4. Three Sorts of Batching
When you have lots of elements and you want to separate them into batches, you have three broad solutions in Reactor: grouping, windowing, and buffering. These three are conceptually close, because they redistribute a Flux<T> into an aggregate. Grouping and windowing create a Flux<Flux<T>>, while buffering aggregates into a Collection<T>.
9.4.1. Grouping with Flux<GroupedFlux<T>>
Grouping is the act of splitting the source Flux<T> into multiple batches, each of which matches a key.
The associated operator is groupBy.
Each group is represented as a GroupedFlux<T>, which lets you retrieve the key by calling its key() method.
There is no necessary continuity in the content of the groups. Once a source element produces a new key, the group for this key is opened and elements that match the key end up in the group (several groups could be open at the same time).
This means that groups:
- Are always disjoint (a source element belongs to one and only one group).
- Can contain elements from different places in the original sequence.
- Are never empty.
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.groupBy(i -> i % 2 == 0 ? "even" : "odd")
.concatMap(g -> g.defaultIfEmpty(-1) //if empty groups, show them
.map(String::valueOf) //map to string
.startWith(g.key())) //start with the group's key
)
.expectNext("odd", "1", "3", "5", "11", "13")
.expectNext("even", "2", "4", "6", "12")
.verifyComplete();
| Grouping is best suited for when you have a medium to low number of groups. The groups must also imperatively be consumed (such as by a flatMap) so that groupBy continues fetching data from upstream and feeding more groups. Sometimes, these two constraints multiply and lead to hangs, such as when you have a high cardinality and the concurrency of the flatMap consuming the groups is too low. |
9.4.2. Windowing with Flux<Flux<T>>
Windowing is the act of splitting the source Flux<T> into windows, by criteria of size, time, boundary-defining predicates, or boundary-defining Publisher.
The associated operators are window, windowTimeout, windowUntil, windowWhile, and windowWhen.
Contrary to groupBy, which randomly overlaps according to incoming keys, windows are (most of the time) opened sequentially.
Some variants can still overlap, though. For instance, in window(int maxSize, int skip) the maxSize parameter is the number of elements after which a window closes, and the skip parameter is the number of elements in the source after which a new window is opened. So if maxSize > skip, a new window opens before the previous one closes and the two windows overlap.
StepVerifier.create(
Flux.range(1, 10)
.window(5, 3) //overlapping windows
.concatMap(g -> g.defaultIfEmpty(-1)) //show empty windows as -1
)
.expectNext(1, 2, 3, 4, 5)
.expectNext(4, 5, 6, 7, 8)
.expectNext(7, 8, 9, 10)
.expectNext(10)
.verifyComplete();| With the reverse configuration (maxSize < skip), some elements from the source are dropped and are not part of any window. |
In the case of predicate-based windowing through windowUntil and windowWhile, having subsequent source elements that do not match the predicate can also lead to empty windows, as demonstrated in the following example:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.windowWhile(i -> i % 2 == 0)
.concatMap(g -> g.defaultIfEmpty(-1))
)
.expectNext(-1, -1, -1) //respectively triggered by odd 1 3 5
.expectNext(2, 4, 6) // triggered by 11
.expectNext(12) // triggered by 13
// however, no empty completion window is emitted (would contain extra matching elements)
.verifyComplete();
9.4.3. Buffering with Flux<List<T>>
Buffering is similar to windowing, with the following twist: Instead of emitting windows (each of which is each a Flux<T>), it emits buffers (which are Collection<T> — by default, List<T>).
The operators for buffering mirror those for windowing: buffer, bufferTimeout, bufferUntil, bufferWhile, and bufferWhen.
Where the corresponding windowing operator opens a window, a buffering operator creates a new collection and starts adding elements to it. Where a window closes, the buffering operator emits the collection.
Buffering can also lead to dropping source elements or having overlapping buffers, as the following example shows:
StepVerifier.create(
Flux.range(1, 10)
.buffer(5, 3) //overlapping buffers
)
.expectNext(Arrays.asList(1, 2, 3, 4, 5))
.expectNext(Arrays.asList(4, 5, 6, 7, 8))
.expectNext(Arrays.asList(7, 8, 9, 10))
.expectNext(Collections.singletonList(10))
.verifyComplete();
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.bufferWhile(i -> i % 2 == 0)
)
.expectNext(Arrays.asList(2, 4, 6)) // triggered by 11
.expectNext(Collections.singletonList(12)) // triggered by 13
.verifyComplete();
9.5. Parallelizing Work with ParallelFlux
With multi-core architectures being a commodity nowadays, being able to easily parallelize work is important. Reactor helps with that by providing a special type, ParallelFlux, that exposes operators that are optimized for parallelized work.
To obtain a ParallelFlux, you can use the parallel() operator on any Flux. By itself, this method does not parallelize the work. Rather, it divides the workload into “rails” (by default, as many rails as there are CPU cores).
In order to tell the resulting ParallelFlux where to run each rail (and, by extension, to run rails in parallel) you have to use runOn(Scheduler). Note that there is a recommended dedicated Scheduler for parallel work: Schedulers.parallel().
Compare the next two examples:
Flux.range(1, 10) .parallel(2) .subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
| We force a number of rails instead of relying on the number of CPU cores. |
Flux.range(1, 10) .parallel(2) .runOn(Schedulers.parallel()) .subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
If, once you process your sequence in parallel, you want to revert back to a “normal” Flux and apply the rest of the operator chain in a sequential manner, you can use the sequential() method on ParallelFlux.
Note that sequential() is implicitly applied if you subscribe to the ParallelFlux with a Subscriber but not when using the lambda-based variants of subscribe.
Note also that subscribe(Subscriber<T>) merges all the rails, while subscribe(Consumer<T>) runs all the rails. If the subscribe() method has a lambda, each lambda is executed as many times as there are rails.
You can also access individual rails or “groups” as a Flux<GroupedFlux<T>> through the groups() method and apply additional operators to them through the composeGroup() method.
'Study' 카테고리의 다른 글
| [Redis Client] Jedis vs Lettuce (Lettuce를 쓰자) (0) | 2022.06.12 |
|---|---|
| [Reactor 3 Reference Guide] 9. Advanced Features and Concepts - 2 (0) | 2021.11.18 |
| [Reactor 3 Reference Guide] 6. Testing (0) | 2021.10.28 |
| [Reactor 3 Reference Guide] 4. Reactor Core Features - 2 (0) | 2021.10.21 |
| [Reactor 3 Reference Guide] 4. Reactor Core Features (0) | 2021.10.13 |

댓글